
Friday, January 20, 2023 - 12:59
American Institutes for Research examines innovation in renewable energy patent study
Social science research starts with a commitment to using our time and resources in addressing problems most affecting society and the human experience. One urgent and globally important area of social science research is renewable energy, specifically, understanding the rate of innovation and adoption in the sector.
At the American Institutes for Research (AIR), we have a team of data scientists that work on transforming, disambiguating, normalizing, and quality assuring all data on the patents granted in the United States. This unleashes opportunity for us to use the data in research and analysis. We chose to develop classification models that predict which patents are related to renewable energy and present our findings at the Conference for Women in Data Science and Statistics this year on 10/8/2022 in St. Louis, MI. We used the Cooperative Patent Classification (CPC) labeling system to find renewable energy patents and look at the most common words used in patent abstracts and titles for this type of patent, demonstrated in the word cloud below.

We built random forest, logistic regression, and naïve bayes machine-learning classification models on the granted Renewable Energy (RE) patents (CPC subclasses under Y02) to predict whether a given patent was RE-related or not. Our efforts focused on searching for the model construction method and parameter choices that optimized the F1-score for Class 1 (predicted as RE-related). Our best-performing model was a random forest classifier and a CountVectorizer (a program to break down sentences into countable parts) on patent abstracts to achieve an F1-score of almost .85 as shown in figure 2.
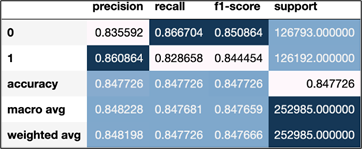
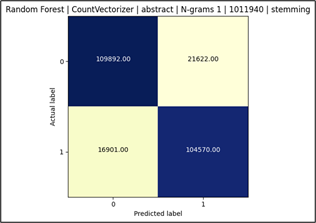
Figure 3 is the confusion matrix for the model described in Fig 2. This matrix shows where correct/incorrect predictions occur. For example, 21,622 patents were predicted to be RE but were not given the Y02 CPC classification.
Enabled by the PatentsView project developed at AIR under the supervision of the Office of the Chief Economist at the USPTO, patent data usage is paramount to holding the federal government accountable for investing and encouraging innovation in science and technology in the areas important to scientists and the public. While challenges to increased domestic and international adoption of solar, wind, and other innovations are interwoven and interdisciplinary, the rate of innovation in renewable energy sector is an important component to analyze and understand as we push to transition away from fossil-fueled power.