PatentsView Data Pipeline
The main source of data for PatentsView sources is from the United States Patent and Trademark Office (USPTO). USPTO releases new patent applications and publications weekly on its bulk data website, which PatentsView uses to create data updates that are released every quarter. PatentsView data move through four phases as illustrated in Figure 1. These phases include data collection, disambiguation, post-processing, and data delivery.
Figure 1. Overview

Data Collection Phase
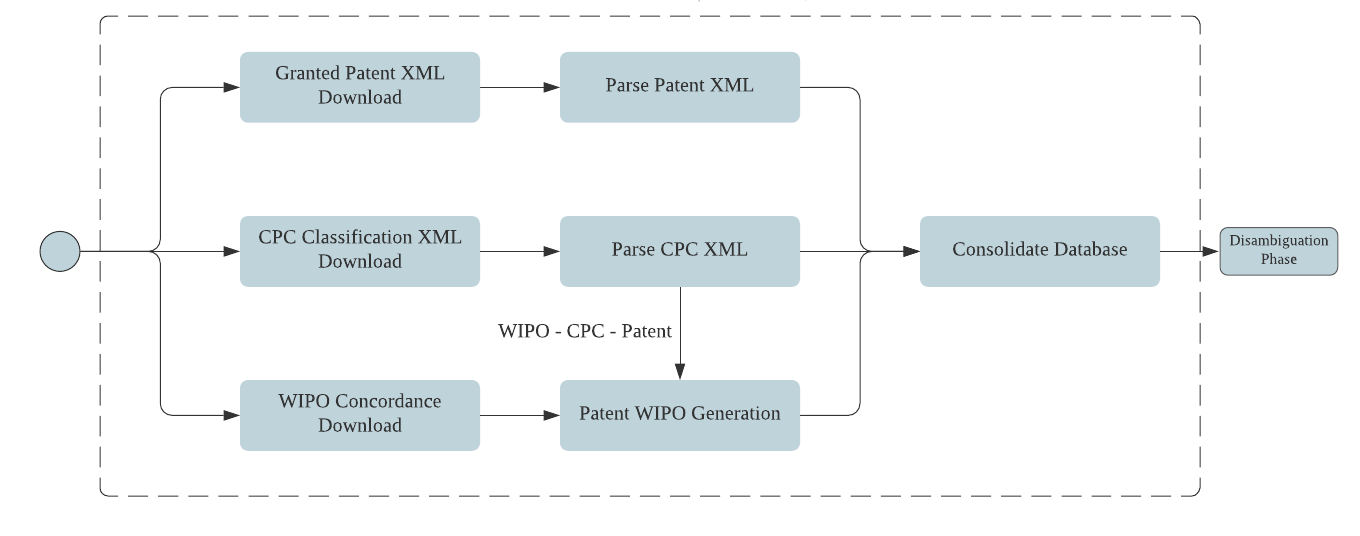
USPTO releases new information in XML file format, which then must be translated into a database- and user-friendly tabular format via a process called XML parsing. PatentsView uses a Python-based process to collect the XML files, parse out the variables and data elements, and update them into the PatentsView database. The process of the data collection phase is illustrated in Figure 2.
Figure 2. Data Collection Phase
Disambiguation Phase
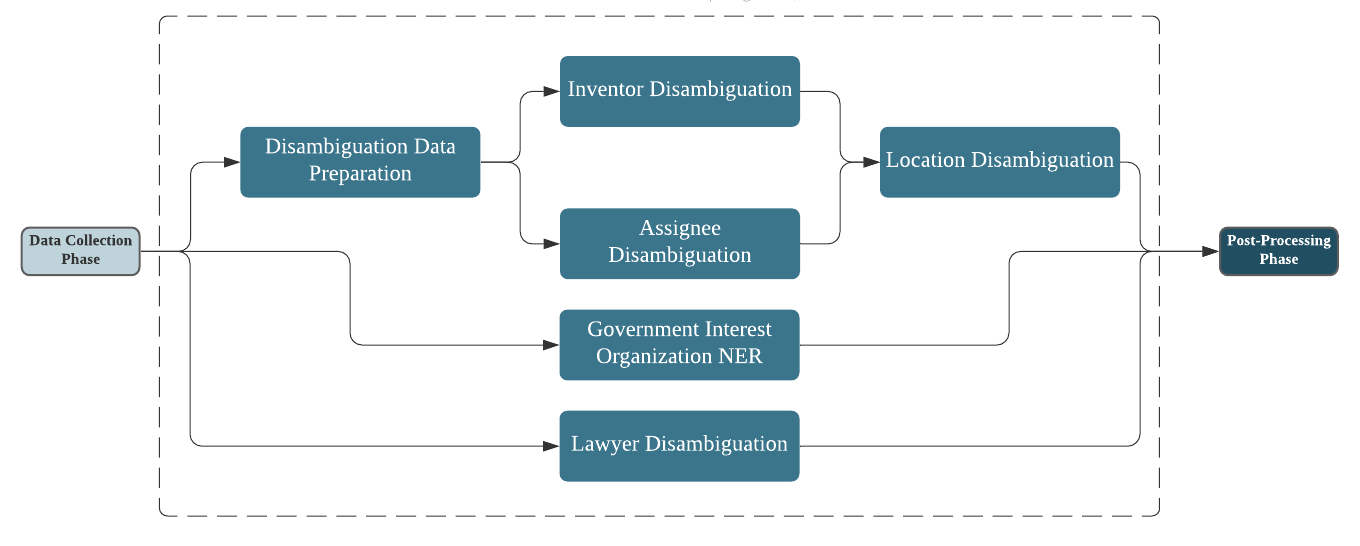
The disambiguation phase focuses on identifying unique entities (i.e., assignee, inventor, location, lawyer, and government organizations) by disambiguating multiple raw entities (see Figure 3). PatentsView uses a hierarchical clustering algorithm to accurately associate unique inventor(s), assignee(s), and location(s) with their patents. PatentsView uses simple string-based methods, such as Jaro-Winkler and Jaccard distances, to disambiguate these patent components and for disambiguation of lawyers and government interest organizations, the documentation for which can be found here.
Figure 3. Disambiguation Phase
Post-Processing Phase
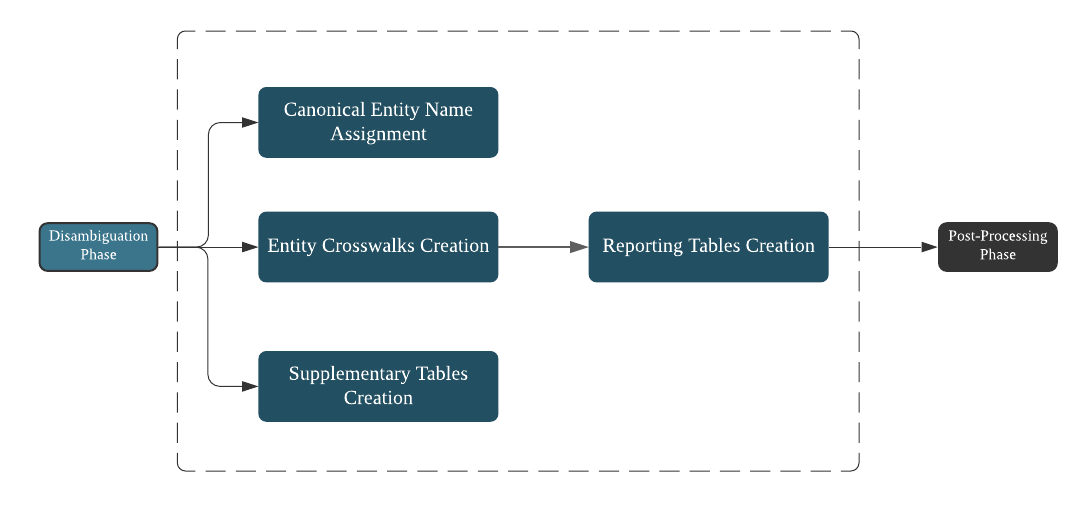
The post-processing phase involves three major activities (see Figure 4). First, the results from disambiguation are used to assign canonical names to different entities (e.g., assignee organization name, inventor name, and location [city, state, and country]). Second, supplementary tables, such as inventor gender and persistent disambiguated IDs, are created. Finally, crosswalk tables between patent and inventor, patent and assignee, patent and location, and so on are created. These tables, along with other parsed data, are used to create an extensive set of calculated data variables, such as number of patents at a location, number of co-inventors of an invention, and so on.
Figure 4. Post-Processing Phase
Data Delivery Phase
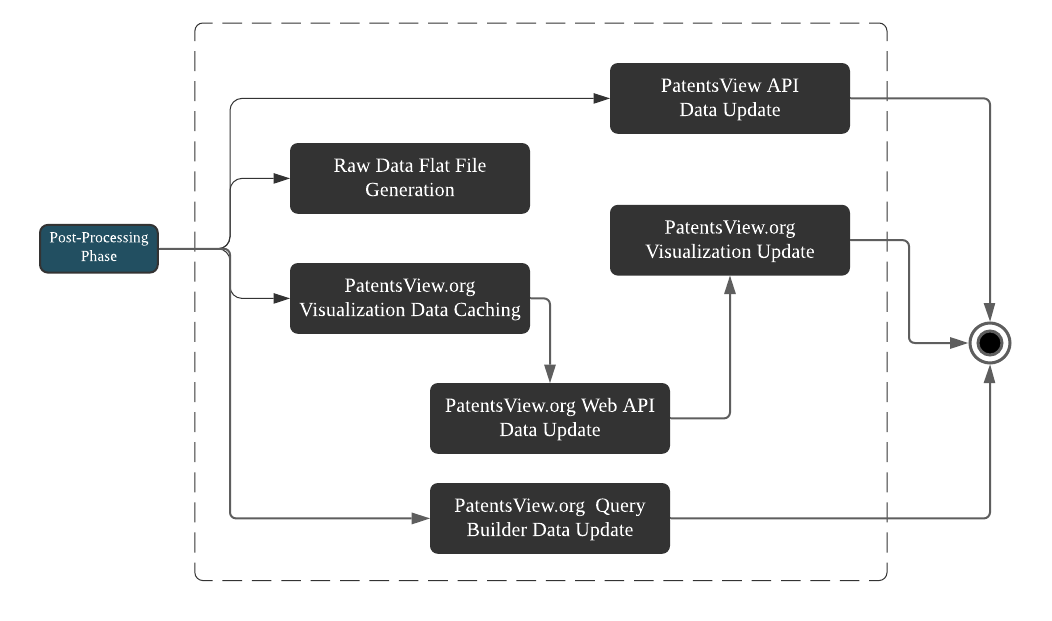
The final phase of the data update pipeline is to deliver the raw data and calculated data elements to the general public through the PatentsView.org website (see Figure 5). This process happens through four channels. The PatentSearch Application Programming Interface (API) and PatentsView Query Builder tool are updated to run queries and searches using the updated data. Then, the bulk download files are regenerated with added data, and finally the website visualizations are updated with the newest counts of patents, inventors, assignees, and locations.
For more information on our API, please visit the API section of the website.
Figure 5. Data Delivery Phase
Because the disambiguation of inventor identities is an ongoing effort, there are likely to be errors observable in the PatentsView data tables. The team welcomes feedback as we continue to improve our disambiguation methodology.