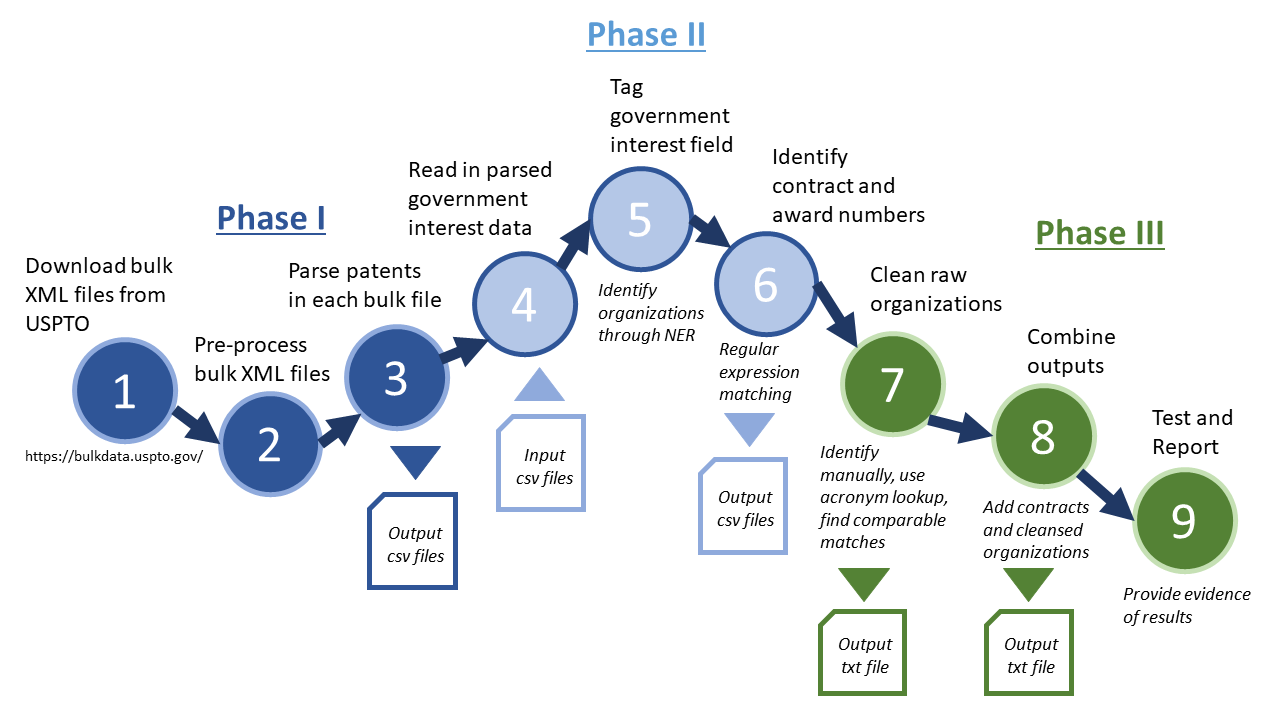
Extraction Process for Government Interest Fields
The extraction process used to identify government organizations, contract numbers, and grant numbers has three phases and nine steps. The phases are (1) the bulk data download process, (2) the extraction process, and (3) the cleaning and quality assurance process. The entire process is shown in Figure 1.
Phase I: Ready USPTO Patent Data for Government Interest Extraction and Processing
Phase I has three steps and starts with raw data from the U.S. Patent and Trademark Office’s (USPTO’s) publicly released information on granted U.S. patents, taken from their downloadable XML files.
Step 1: Download bulk files from USPTO
Patent files are downloaded in XML format from USPTO’s bulk download site at https://bulkdata.uspto.gov/ under the heading “Patent Grant Full Text Data (No Images) (JAN 1976–PRESENT).” In 2018, this step was incorporated into the PatentsView automated data processing pipeline, making it automatic.
Step 2: Preprocess bulk files
The XML bulk download files undergo “preprocessing” that standardizes headers for matching across files. Note that this does not change any of the downloaded data.
Step 3: Parse patents
A separate output directory is generated for each preprocessed bulk file. Patent information is extracted and written to the corresponding bulk file directory with government interest data written to “government_interest.csv” in each bulk file output directory.
Phase II: Extract Raw Government Interest Field Data
All steps in phase II are contained within a single python program, “NER.py.” NER is a java-based Name Entity Recognition library maintained by Stanford. This process was originally written in Perl but converted to Python 3 with everything else in 2018.
NER enables the identification of organizations without requiring a prepopulated list of known federal agencies. It was selected due to the number of variations found in the patent data. For example, the National Institutes of Health can be found in the data as “NIH,” “N.I.H.,” “National Institute of Health,” and “National Institutes of Health.” NER helps to identify variations to prepare the data for phase III.
Figure 1. Methods Overview: Steps 1-9
Step 4: Read the data
The government_interest.csv files from each output directory are combined into one complete output file for processing.
Step 5: Tag government interest field
To capture all found organization entries, NER is run on the government interest field using three classifiers: (1) a model where locations, persons, and organizations are tagged; (2) a model where locations, persons, organizations, and miscellaneous items are identified; and (3) a model where locations, persons, organizations, money, percentages, dates, and times are tagged. Content identified as organizations by any of the models is retained and processed.
In early testing, the combination of all three models was shown to provide better results than running one in isolation. This is because NER is a machine-learning approach that returns slightly different results for each model. Duplicates are removed after combining the three models. An example of this step’s output, with organizations tagged, follows:
The <ORGANIZATION>United States
Government</ORGANIZATION> has rights in this invention under Contract No. DE-AC36-08GO28308 between the <ORGANIZATION>United States Department of
Energy</ORGANIZATION> and the <ORGANIZATION>Alliance for Sustainable Energy</ORGANIZATION>,
<ORGANIZATION>LLC</ORGANIZATION>, the Manager and Operator of the <ORGANIZATION>National Renewable Energy Laboratory</ORGANIZATION>.
Step 6: Identify contract and award numbers
The algorithm begins by splitting text in the government interest field on spaces. Grant or award numbers that match on capital letters and/or numbers are then isolated as seed identifiers. Some grant or award numbers span multiple spaces (i.e., word boundaries), so it is necessary to look backward and forward to determine whether part of the number exists across word boundaries. If so, these identifiers are combined, and duplicates are removed from the seed list. In addition, unnecessary data that are identified through this algorithm, such as telephone numbers, e-mail addresses, and zip codes, are removed from the list.
Below is an example of how this algorithm works: Award numbers CA48902 and CA09206 are identified as seeds, and NCI R29 and NRSA are combined with the grant number.
This invention was made with Unites States Government support awarded by the National Institute of Health (NIH), Grant Nos. NCI R29 CA48902 and NIH Training Grant NRSA CA09206. The United States Government has certain rights in this invention.
The text is then searched for remaining award numbers that match either of the following rules: (1) The award number starts with an alphanumeric character and the second character is alphanumeric or “-.” This is then followed by at least one more digit with no spaces, and the award number ends with one or more alphanumeric characters (e.g., CA48902). (2) The award number begins with one to three alphanumeric characters, where the alphabetical characters are all capital letters with a single space followed by one or more alphanumeric characters, and the award number ends in a digit (e.g., DOD 05118004).
Phase III: Prepare Final Government Interest Dataset
After tagging and identification of organizations as well as contract and award numbers, the data must be cleaned and tested for quality before creating the final data sets. USPTO stakeholders and the PatentsView team decided that it would be best to include only the most commonly occurring federal organizations. Nonfederal or foreign organizations (including companies, universities, and state agencies) are not included in the government interest agency extraction process.
Step 7: Clean raw organizations
The output of the NER program is matched up to a master list of more than 300 U.S. government organizations and their corresponding acronyms to clean organization names, resolve misspellings, and remove any nonfederal organizations. The list was created manually from Wikipedia and is augmented with new organizations each time the program is run on new data. The code to perform this cleaning was originally written in R but is now in Python 3.
The NER program takes as input a list of all organizations parsed from USPTO XML files and utilizes a fuzzy matching algorithm to compare these organizations with the master list. The fuzzy matching algorithm determines the ratio of characters in the organization’s name that match an organization on the master list, categorizing organizations as nonmatches, possible matches, or solid matches based on thresholds set before matching. The results are then manually analyzed for validity.
Step 8: Combine outputs
The final output, which contains the cleaned organization names from step 7, is added to the end of the final output produced in step 6.
Step 9: Test and report
As part of the PatentsView pipeline process, the government interest data are reviewed using both automated and manual mechanisms. Comparisons are generated on total number by year of government interest statements, contract and award numbers, and distribution of organizations. These comparisons are then evaluated based on previous PatentsView data to ensure accuracy. In addition, samples of the update data are manually reviewed by taking one sample from the completed updated data set and one from patents that are assigned “U.S. Government” as a government interest organization.