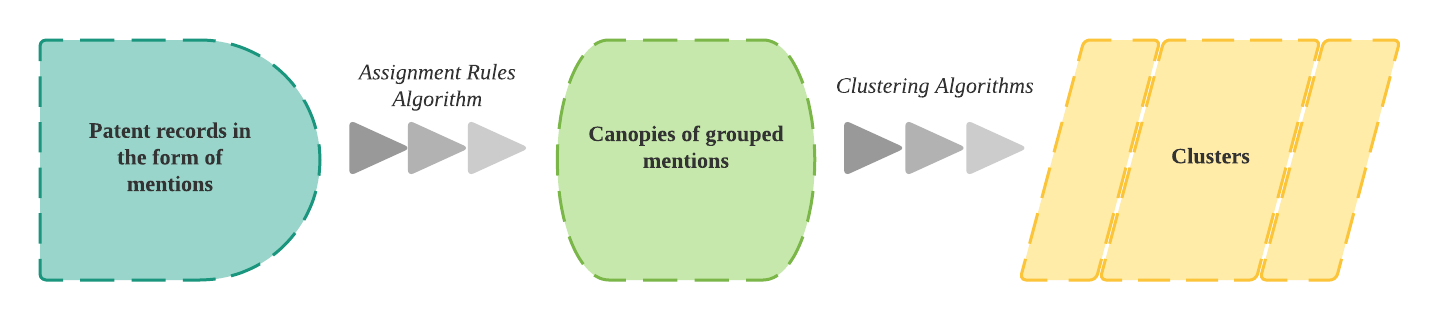
Disambiguation Step 1: Constructing Canopies
The first step in the disambiguation process is to identify records that might represent the same entity (i.e., inventor or assignee). This process uses a series of rules to group mentions into canopies, and each mention of an inventor or an assignee could be included in multiple canopies. The rules for forming canopies were developed empirically by testing many different approaches until a set of rules that divided the mentions efficiently was established.
Rules for clustering assignees are different than the rules used for clustering inventors. To further break down how this process works, one must understand the difference between patent assignees and inventors.
- The inventor associated with a patent refers to the individual that initially conceived of the invention for which the patent confers rights.
-
The assignee refers to the entity that holds property rights for the patent. This is typically a company, university, research lab, or other patent-owning entity.
Sometimes, the inventor and assignee are the same, but it is more likely that a company or organization will be the assignee. Many times, patents are developed by employees of an organization that reserves the property rights for patents associated with any invention created by an employee while working for them.
Breaking Down Canopies Into Clusters
Assignee Canopies
The algorithm uses an exact four-character overlap of the beginning of any word or name of the organization as the criteria for creating assignee canopies.[1] For example, if we have the four mentions (a) “General Electric,” (b) “General Electirc,” (c) “Motorola,” and (d) “Motorola Electronics,” the algorithm would create three separate canopies that represent three distinct sets of four characters: “gene,” “elec,” and “moto.” Assignees with multiple word names are grouped into canopies of the first four letters of each word in the organization name (e.g. “Blue Ocean Systems” would be included in the “blue,” “ocea,” and “syst” canopies). Figure 2 is a visual representation of how these mentions are divided into canopies. Note that some mentions (e.g., “General Electric”) appear in multiple canopies.
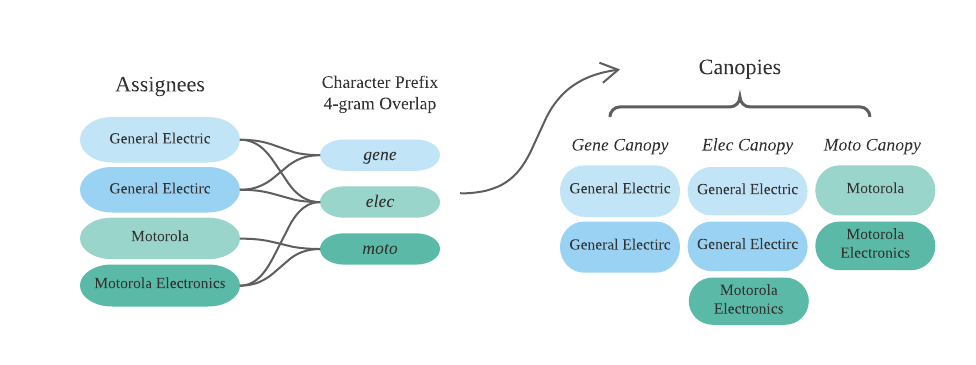
The approach described for organizations is also used for assignees who are individuals. Canopies are created based on the overlap between the first four characters of the individual name. The more in-depth approach described for inventors (in the next section) is not used for assignees who are individuals because there are relatively few mentions in this category and disambiguation using this approach is therefore not computationally taxing.
Inventor Canopies
Inventor canopies, unlike assignees, are nonoverlapping. Each inventor is assigned to a single canopy that is based on the inventor’s first two initials and last name.
Figure 3 shows this process visually.

[1] In computer science terms, an exact four-character overlap is called a character prefix 4-gram overlap.