COVID-19 disrupted all our lives, but it also opened the door to innovation. The speed at which researchers, companies, and universities developed new tests, treatments, and vaccines was unprecedented. A new report from the U.S. Patent and Trademark Office (USPTO) Office of the Chief Economist found that much of the innovation around diagnosing COVID-19 was led by universities and small companies.
Diagnosing COVID-19: A perspective from U.S. patenting activity looks at patents filed that relate to diagnosing the COVID-19 as it emerged and spread. It contributes to a growing body of research that examines how innovation responds to crisis. The report was released on October 23.
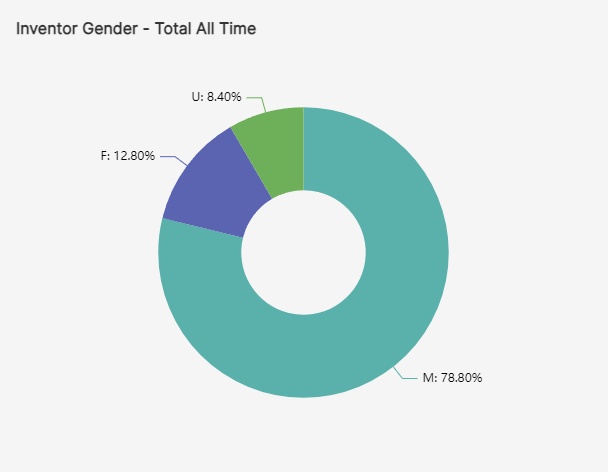
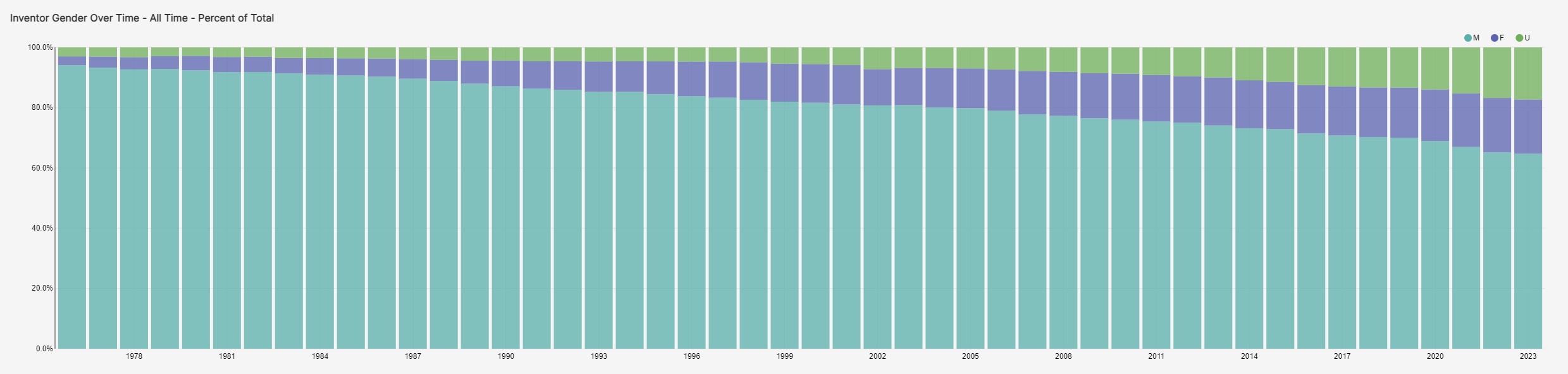
The research team used PatentsView to identify patents that include a government interest statement. This helped them to identify which patents were funded by government agencies.
Key Findings from the Report
The report looked at patents filed or issued through April 2023 that helped identify and detect the SARS-CoV-2 virus. Some of the key findings in the report included:
-
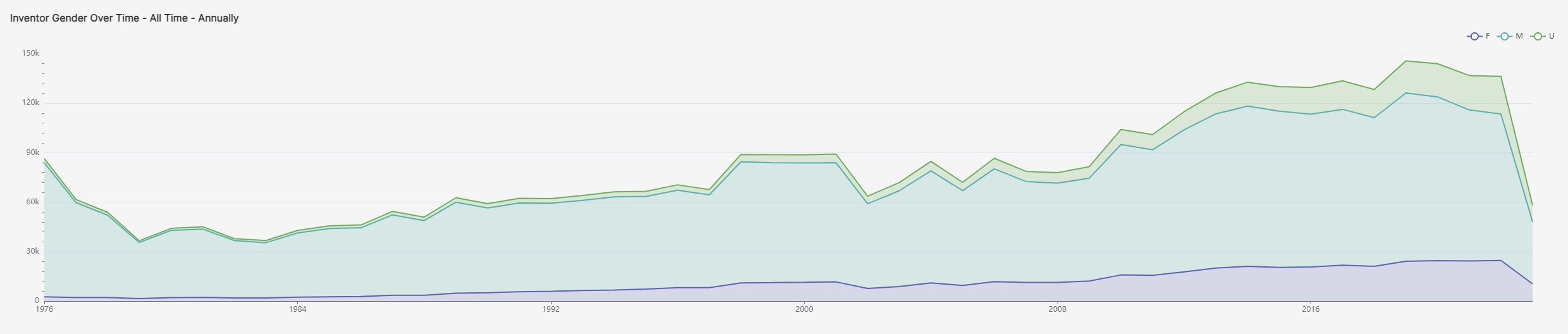
The number of COVID-19 diagnostic patent filings that were published by the USPTO surged and then receded in the months following the emergence of the coronavirus—such publications peaked in the fourth quarter of 2021, which generally reflects applications filed in April, May, and June of 2020.
-
COVID-19 diagnostic filings make up about 30% of all COVID-19 public patent filings, hovering at about one out of every three COVID-19 filings at the USPTO.
-
Small companies and universities led the way in COVID-19 diagnostic public patent filings at the USPTO with the top filer being a diagnostic startup company.
-
U.S. government financial support helped spur COVID-19 diagnostic inventions, as indicated by government interest statements contained in the filings. About 10.7% of all COVID-19 public patent filings show government support, with the National Institutes of Health leading other agencies.
-
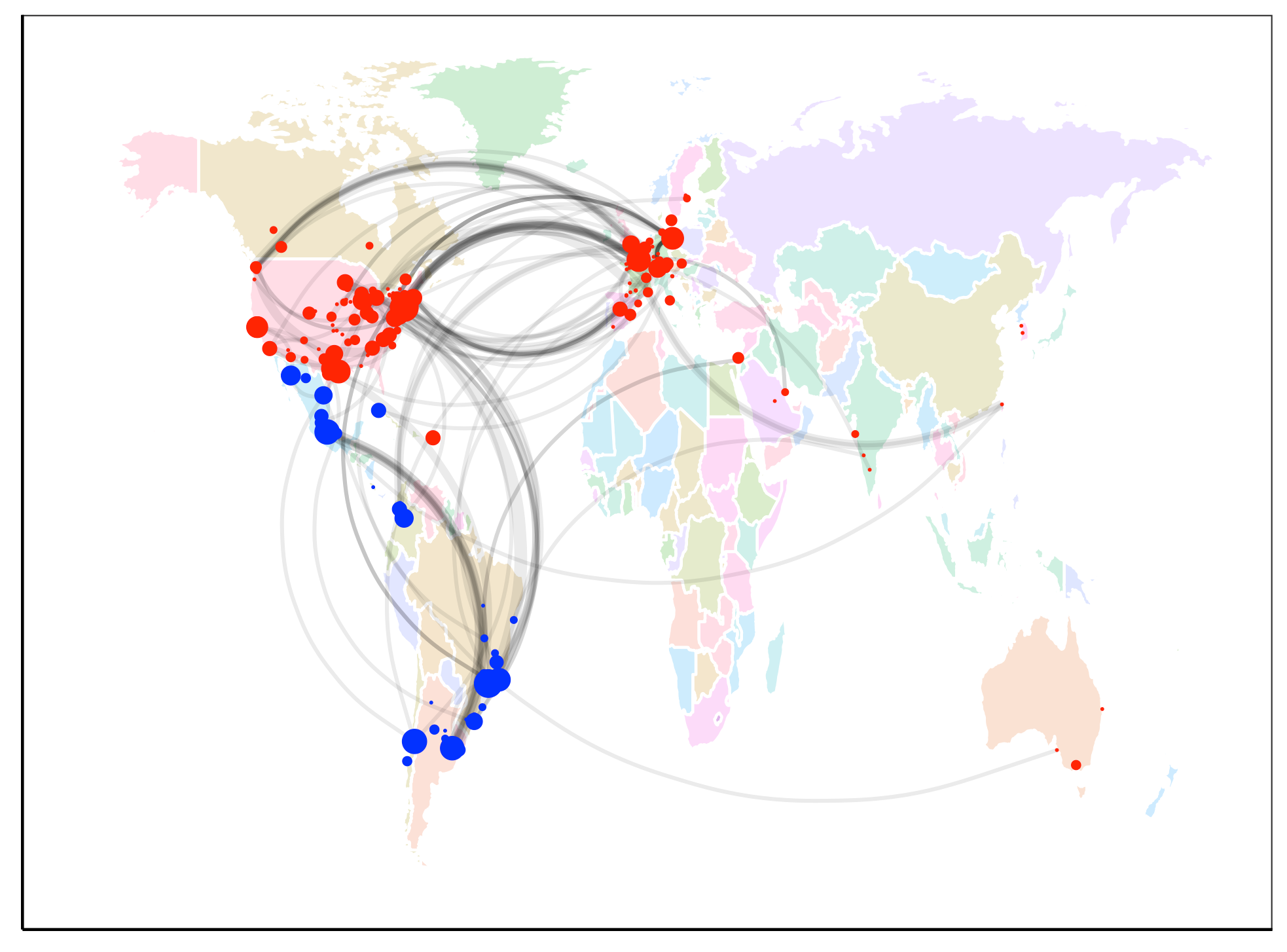
U.S.-based applicants are leading those from other countries in U.S. COVID-19 diagnostic public patent filings, making up most of the volume, including most of the top 21 applicants.
-
COVID-19 diagnostic public patent filings are concentrated in a few technologies such as analyzing materials and measuring enzymes, nucleic acids, and microorganisms.
-
Many applications for inventions directed at COVID-19 diagnostics also disclose methods of treatment (about 8.6%). For instance, inventions for antibodies may diagnose and treat COVID-19.
-
Among 5,585 global COVID-19 diagnostic patent families found in the study, 47% have at least one filing at the China National Intellectual Property Administration (CNIPA), the most of any jurisdiction.
Read the Full Report
The full report is available on the USPTO website.